引 言
人工神经网络(Artificial Neural Network,ANN)是一种类似生物神经网络的信息处理结构,它的提出是为了解决一些非线性,非平稳,复杂的实际问题。目前实现ANN还主要依靠软件程序.但是依靠程序很难达到实时性的要求。
神经网络在FPGA上实现是独立于冯・诺依曼架构,利用FPGA的并行性,在一些实时性要求很强的领域应用。通用计算机虽然编程容易,但是很多时间浪费在分析指令,读出写入数据等。于是人们想利用ASIC(专用计算芯片)完成神经网络的计算任务,但是由于资源有限,这种芯片只限于实现特定的算法结构和小规模网络,而且专用芯片的制作成本很高,只适合大批量生产。
可编程逻辑器件FPGA的出现给IC设计行业一个很强的工具,它可以小成本的开发一些专用芯片,如果开发是成功的可以考虑流片生产。用FPGA实现神经网络比ASIC神经计算单元更容易实现,利用可编程逻辑,FPGA可以实现像软件一样的设计灵活性,特别是对于复杂网络,设计周期大大缩短,其内部的重构逻辑模块(Configurable Logic Blocks,CLBs)包含若干逻辑单元,利用固有的可重构路径结构可以实现高效率的连接。此外,现在正在开发中的一种神经计算芯片为神经网络的实现提出了一种新的有效方法。
1 FPGA实现神经网络关键问题分析
(1)选择合适的神经网络及其拓扑结构
不同的神经网络有不同的应用,而且不同的网络完成知识表达的机理是不同的,某一个神经网络不是万能的.对于实际问题,首先要做的就是选择针对性的神经网络,如线性分类问题可以用简单的感知器,对于复杂的分类问题,函数逼近问题可以使用BP网络,对于一些聚类问题可以使用径向基(RBF)网络等。以BP网络结构为例,这种被广泛采用的架构由具有错误反向传播算法的多层感知器构成(Multilayer Perceptrons u-sing Back-Propagation,MLP-BP),训练一个BP网络主要的问题就在于:训练开始之前,对于网络拓扑结构缺乏一种明确的确定方法。而进行各种拓扑结构的实验并不那么容易,因为对于每一个训练周期都要消耗很长的时间,特别是复杂的网络,更是如此;其次,对于硬件而言,最合适的网络运算法则不仅在于它达到收敛有多么快,还要考虑是否容易在硬件上实现且这种实现代价和性能如何;另外,对于同一种NN(Neural Net-work)。其拓扑结构对网络的收敛特性以及知识表达特性都有影响,一般增加网络的神经元或者神经元的层数,是可以增加网络的逼近能力,但是可能会影响网络的学习收敛情况,而且还可能会因为过适应(Overfit)而失去泛化能力。
(2)正确选择数值表达形式
精度的选择对处理密度(与耗费的硬件资源成反比)有直接影响。其中浮点数可以在计算机中表达实数,它有相对高的精度和大的动态范围,使用浮点数使得计算更为精确,但是在FPGA上实现浮点数运算是一个很大的挑战,而且会耗费很多硬件资源。尽管如此,加拿大研究人员Medhat Moussa and Shawki Arei-bi仍然实现了浮点数的运算,并进行了详细的对比分析。
对于MLP-BP而言,Holt and Baker凭借仿真和理论分析指出16为定点(1位标志位,3位整数位和12位小数位)是最小可允许的精度表示(指可以达到收敛)。以逻辑XOR问题为例,文献[1]中表格2.5(见表1)表明与基于FPGA的MLP-BP浮点法实现相比,定点法实现在速度上高出12倍,面积上是浮点实现的1/13,而且有更高的处理密度。

同时数据也说明基于FPGA的16位定点MLP-BP实现在处理密度上高于基于软件方法的MLP-BP实现,这最好地证明可重构计算方法的处理密度优势。应该说,在这种应用中浮点数远不如定点数合适。但是定点数表示的缺点在于有限精度,尽管如此,对于不同的应用选择合适的字长精度,仍然可以得到收敛。因此,目前基于FPGA的ANN大多数是使用定点数进行计算的。
(3)门限非线性激活函数(Non-linear activationFunction)的实现
ANN的知识表达特性与非线性逼近能力,有很大部分源自门限函数。在MLP网络中,门限函数大部分是非线性函数(少数是线性函数,如输出层的门限函数),但是非线性传递函数的直接硬件实现太昂贵,目前实现门限函数的方法主要有:查表法(look-up ta-ble)、分段线性逼近、多项式近似法、有理近似法以及协调旋转数字计算机(Coordinated Rotation Digital Com-puter,CORDIC)法则,CORDIC法则实现函数的优点在于同一硬件资源能被若干个函数使用,但是性能相当差,因此较少使用。而高次多项式近似法尽管可以实现低误差近似,但是实现需要耗费较高硬件资源。相对而言,查找表法和分段线性逼近法(注意:查找表不易太大,否则速度会慢且代价也大)更适合FPGA技术实现。其中分段线性近似法以y=c1+c2x的形式描述一种线性连接组合(如图1所示),如果线性函数的系数值为2的幂次,则激活函数可以由一系列移位和加法操作实现,许多神经元的传递函数就是这样实现的,而查找表法则是将事先计算的数值依次存储在需要查询的存储器中来实现。
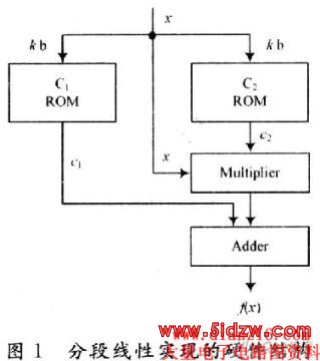
(4)面积节省及相关问题
为了最小化神经元实现的面积,组成每个神经元的各个HDL算法模块的面积也应该最小。乘法器以及基本的传递函数(例如,sigmoid激活函数tanh)是最占用面积的,这类问题非常依赖于所要求的精度,尽管神经网络常并不要求很精确的计算,但是不同的应用所要求的精度不同。一般来讲,浮点运算要比定点运算需要更大的面积,比如浮点运算中的并行加法器本质上是定点运算超前加法器加上必要的逻辑块,减法器、乘法器也类似如此,这在激活函数实现方面更加突出,文献[1]中面积优化对比显示,32位浮点运算要比16位定点运算大250倍。另外,对于小型网络,分布式存储器很适合权值存放,但是对于大型网络,权值存储器不应该被放置在FPGA中,因此当ANN得到有效实现的时候,就要认真考虑存储器的存取问题。其次,神经网络应用有一个显著的缺陷:在神经计算方面,不同运算的计算时间和实现面积并不平衡。在许多标准神经模式中,计算时间的大部分用在需要乘法器和加法器的矩阵向量运算中,而很多耗费面积的运算如激活函数,又必须被实现(它们占用很少的运算时间),而FPGA的面积是严格一定的,因此可将面积的相当一部分用来实现这些运算,以至于FPGA仅剩的一小部分却实现几乎所有的运算时间。
(5)资源和计算速度的平衡(Trade-off)
对于FPGA,科学的设计目标应该是在满足设计时序要求(包括对设计最高频率的要求)的前提下,占用最少的芯片资源,或者在所规定的占用资源下,使设计的时序余量更大,频率更高。这两种目标充分体现了资源和速度的平衡思想。作为矛盾的两个组成部分,资源和速度的地位是不一样的。相比之下,满足时序、工作频率的要求更重要一些,当两者冲突时,采用速度优先的准则。
例如,ANN的FPGA实现需要各种字长的乘法器,如果可以提出一种新的运算法则,从而用FPGA实现变字长的乘法器,则可以根据需要调整字长,从而提高运算速度的可能性,其中,基于Booth Encoded opti-mized wallence tree架构(见图2)就可以得到快速高效的乘法器,这种方式实现的乘法器比现在所用的基于FPGA的乘法器的处理速度快20%)。
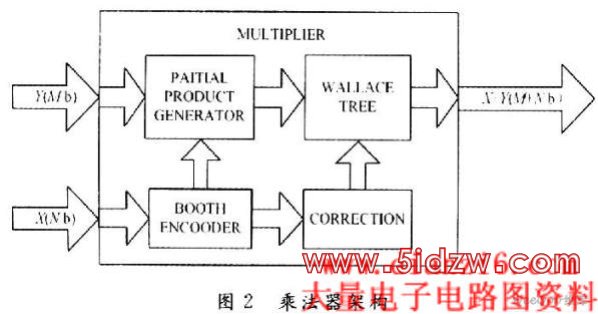
(6)亟待解决的问题
FPGA凭借其如同软件实现一样的灵活性,集合了硬件实现高效和并行性的优点,好像非常适合神经实现的正常需要,但是,FPGA的二维拓扑结构不能处理标准神经网络规则但复杂的连线问题,而且FPGA仍然实现很有限的逻辑门数目,相反,神经计算则需要相当耗费资源的模块(激活函数,乘法器)。这样对于FP-GA,可用的CLBs中部分将被用来增加路径容量(连线),导致计算资源的丢失。一般的方法只能实现很小的低精度神经网络,连线问题不能依靠几个具有比特序列算法的可重构FPGA以及小面积模块(随机比特流或者频率)解决。
,基于FPGA的人工神经网络实现方法的研究